AP Initialization and Overview of Its Implementation
Before running any software code, hardware selects the processor that gets initialized and starts executing firmware code. This processor is called a bootstrap processor (BSP) and is basically the sole active processor until an operating system starts up the rest of the processors.
Those non-BSP are called APs and are initialized by the BSP sending a sequence of inter processor interrupts (IPIs): INIT, Startup IPI, and the 2nd Startup IPI. This sequence is also referred to as INIT-SIPI-SIPI.
As noted in the previous post, a hypervisor that starts earlier than the operating system needs to handle VM-exists caused by those IPIs. But when that happen exactly?
On Linux, this is relatively easy to find out. Searching "STARTUP IPI" in Linux source code or other developers' forums leads you to the implementation, smpboot.c. On Windows 10, this is done in HalpApicStartProcessor, called from kernel's KeStartAllProcessors, in short. The stack trace is shown below:
00 hal!HalpApicStartProcessor
01 hal!HalpInterruptStartProcessor
02 hal!HalStartNextProcessor
03 nt!KeStartAllProcessors
04 nt!Phase1InitializationDiscard
05 nt!Phase1Initialization
06 nt!PspSystemThreadStartup
07 nt!KiStartSystemThread
01 hal!HalpInterruptStartProcessor
02 hal!HalStartNextProcessor
03 nt!KeStartAllProcessors
04 nt!Phase1InitializationDiscard
05 nt!Phase1Initialization
06 nt!PspSystemThreadStartup
07 nt!KiStartSystemThread
Let us look into little more details on Windows 19H1 (18362.1.amd64fre.19h1_release.190318-1202) without Hyper-V enabled. To be clear, the execution path varies drastically if Hyper-V is enabled.
KeStartAllProcessors captures various system register values with KxInitializeProcessorState, updates per processor book keeping data structures and calls HalStartNextProcessors for each registered processor one by one to start all of them.
High Level Flow
KeStartAllProcessors captures various system register values with KxInitializeProcessorState, updates per processor book keeping data structures and calls HalStartNextProcessors for each registered processor one by one to start all of them.
HalpInterruptStartProcessor builds stub code and temporal data structures required for APs to go through real-mode, 32 bit protected-mode, and long-mode, such as page tables, GDT, and IDT. HalpLowStub (that is PROCESSOR_START_BLOCK according to this talk by Alex Ionescu) is the address of where those are build and the very entry point of the AP. We will review the entry point code and how it goes up to the NT kernel.
HalpInterruptStartProcessor, after the stub is built. executes HalpApicStartProcessor which is responsible for issuing the INIT-SIPI-SIPI sequence. Pseudo code of this function is shown below.
NTSTATUS
HalpApicStartProcessor(
UINT64,
UINT32 LocalApicId,
UINT64,
UINT32 StartupIp
)
{
//
// Assert INIT, then de-assert it. INIT-deassert IPI is done only for backword
// compatibility.
// See: 10.4.7.4 Local APIC State After It Receives an INIT-Deassert IPI
//
HalpApicWriteCommand(LocalApicId, 0xC500); // APIC_INT_LEVELTRIG | APIC_INT_ASSERT | APIC_DM_INIT
KeStallExecutionProcessor(10u);
HalpApicWriteCommand(LocalApicId, 0x8500); // APIC_INT_LEVELTRIG | APIC_DM_INIT KeStallExecutionProcessor(200u);
// // Compute the SIPI message value and send it. // "the SIPI message contains a vector to the BIOS AP initialization code (at // 000VV000H, where VV is the vector contained in the SIPI message)." // See: 8.4.3 MP Initialization Protocol Algorithm for MP Systems // sipiMessage = (StartupIp & 0xFF000 | 0x600000u) >> 12; // APIC_DM_STARTUP HalpApicWriteCommand(LocalApicId, sipiMessage); KeStallExecutionProcessor(200u); HalpApicWaitForCommand(); KeStallExecutionProcessor(100u);
// // Send the 2nd startup IPI. // HalpApicWriteCommand(LocalApicId, sipiMessage); KeStallExecutionProcessor(200u);
HalpApicWriteCommand(LocalApicId, 0x8500); // APIC_INT_LEVELTRIG | APIC_DM_INIT KeStallExecutionProcessor(200u);
// // Compute the SIPI message value and send it. // "the SIPI message contains a vector to the BIOS AP initialization code (at // 000VV000H, where VV is the vector contained in the SIPI message)." // See: 8.4.3 MP Initialization Protocol Algorithm for MP Systems // sipiMessage = (StartupIp & 0xFF000 | 0x600000u) >> 12; // APIC_DM_STARTUP HalpApicWriteCommand(LocalApicId, sipiMessage); KeStallExecutionProcessor(200u); HalpApicWaitForCommand(); KeStallExecutionProcessor(100u);
// // Send the 2nd startup IPI. // HalpApicWriteCommand(LocalApicId, sipiMessage); KeStallExecutionProcessor(200u);
Note that those HalpApic functions are the function pointers that are set for APIC or APICx2 according to the system configurations.
Then let us review how APs get initialized by following the stub code.
AP Initialization Code
HalpRMStub - Real-Mode
The entry point code is symbolized as HalpRMStub. As the name suggests, running in the real-mode, right after the SIPI. As seen in the screenshot below, the stub code sets CR0.PE (0x1) enabling the protected mode and jumps out to somewhere.

As it is 16bit code, the instructions show by Windbg is slightly broken. Below is the correct output.

Also, let us switch to physical addresses since the code runs in the real-mode.
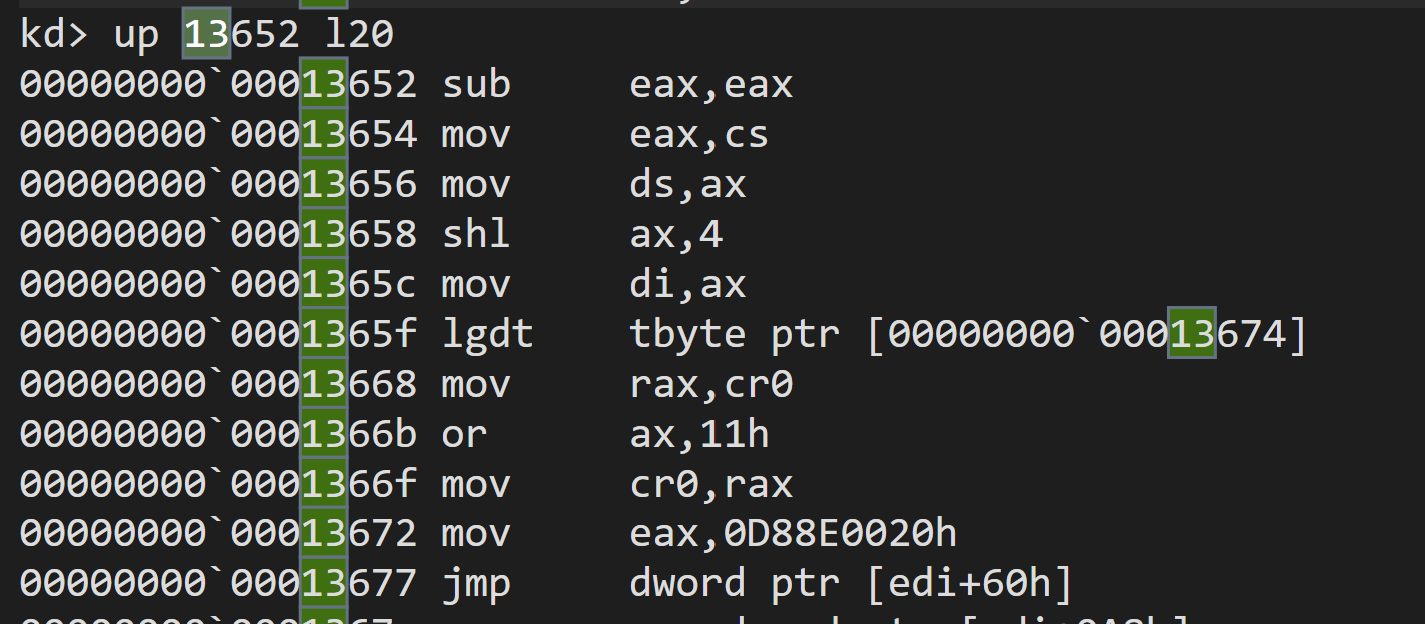
From code, the value of EDI is known to be 0x13000, because EDI is CS << 4, and CS is [19:12] of the IP, as stated in 8.4.3 (see the comment in the above pseudo code).
HalpPMStub - Protected-Mode
Following EDI+0x60 navigates us to the protected mode stub implemented as HalpPMStub.

This code is responsible for switching to the long-mode. As seen below, it
- sets CR4.PSE (0x1000),
- updates IA32_EFER, then
- sets CR0.PG (0x8000000), to activate the long-mode (see the second screenshot).

HalpLMIdentityStub - Long-Mode under Identity Mapping
The JMP leads to the short stub whose sole responsibility is to retrieve the value of CR3 that can permanently be used, that is, the same value as that of BSP.

As the processor should already working with the virtual addresses, let us switch to it.

HalpLMStub - Long-Mode
This is the final stub that APs go through. The first thing this stub does is to apply the permanent CR3 value to have the same memory layout as BSP (and any other already initialized APs) followed by invalidation of TBLs.

After switching the page tables, it performs various initialization, and at the end, it jumps out to where RDI+0x278 indicates.

Conclusion
We reviewed how Windows initiates execution of APs with the INIT-SIPI-SIPI sequence and how APs go though from real-mode to the regular NT kernel initialization function on Windows 10 19H1 without Hyper-V.
Hopefully, you enjoyed this post and gained more contexts on INIT-SIPI-SIPI VM-exits you may see while writing a hypervisor too.


